Le web et les contenus
Naviguer sur la Toile, le web (ou le ouèb), l'Internet — peu importe ici (pour l'instant) la manière dont on appelle ce Réseau — n'est pas quelque chose d'intuitif. Il n'est pas évident de comprendre comment sont agencés les contenus et par quels procédés je peux non seulement y accéder, mais aussi pouvoir le faire plusieurs fois, les retrouver au même endroit, ou comprendre pourquoi ils n'y sont plus. En somme, il faut expliquer ce que signifie « naviguer » avec un navigateur, ce logiciel indispensable pour passer de l'affichage d'un contenu web à l'autre. Mais tout cela est soumis à certaines règles, à la fois techniques et juridiques.
L'URL : savoir où je me trouve sur Internet
L'URL (Uniform Resource Locator — littéralement « localisateur uniforme de ressource ») indique l'adresse d'un contenu sur Internet. Imaginez-la comme une véritable adresse postale dans le grand village d'internet.
Le logiciel qui permet de se rendre à cette adresse est le navigateur. Il affiche à l'écran le contenu de la page que vous souhaitez voir, tout comme l'adresse de votre maison permet au facteur de savoir exactement à quelle porte sonner.
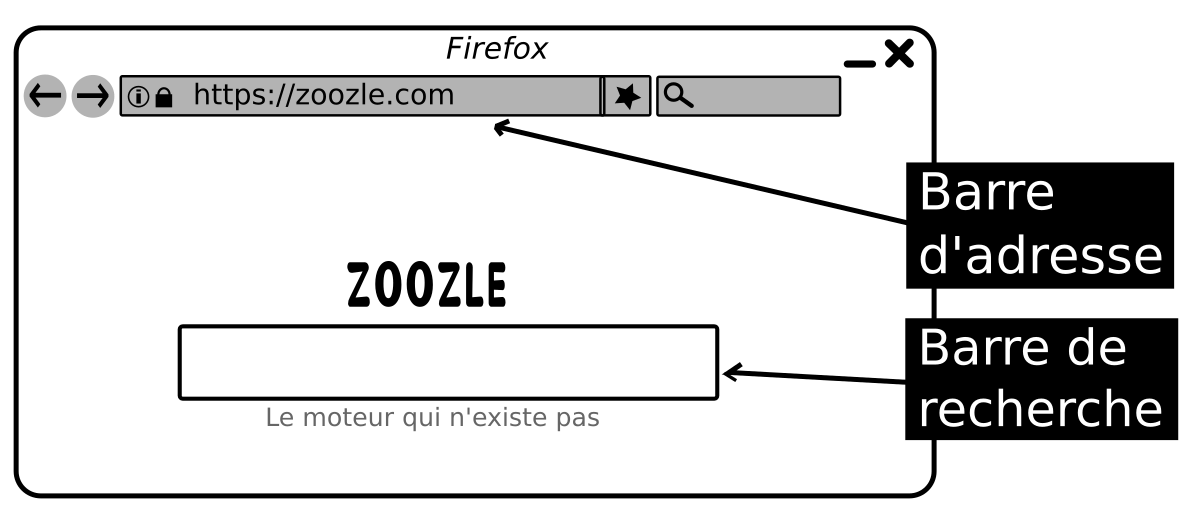
Sur la plupart des navigateurs, elle apparaît en haut dans un cadre que vous pouvez éditer, c'est-à-dire que vous pouvez directement taper dans l'espace prévu cette adresse si vous la connaissez.
On appelle cet endroit la barre d'adresse et elle ne doit pas être confondue avec la barre de recherche d'un moteur de recherche qui apparaît souvent en première page lorsque vous lancez votre navigateur.
Pour passer d'un contenu à un autre, d'une page à une autre, on clique sur des liens. Un lien est figuré par un texte souligné ou de couleur différente ou encore une image. Dans tous les cas, lorsque le pointeur de la souris est positionné dessus, l'URL de destination s'affiche en bas à gauche du navigateur.
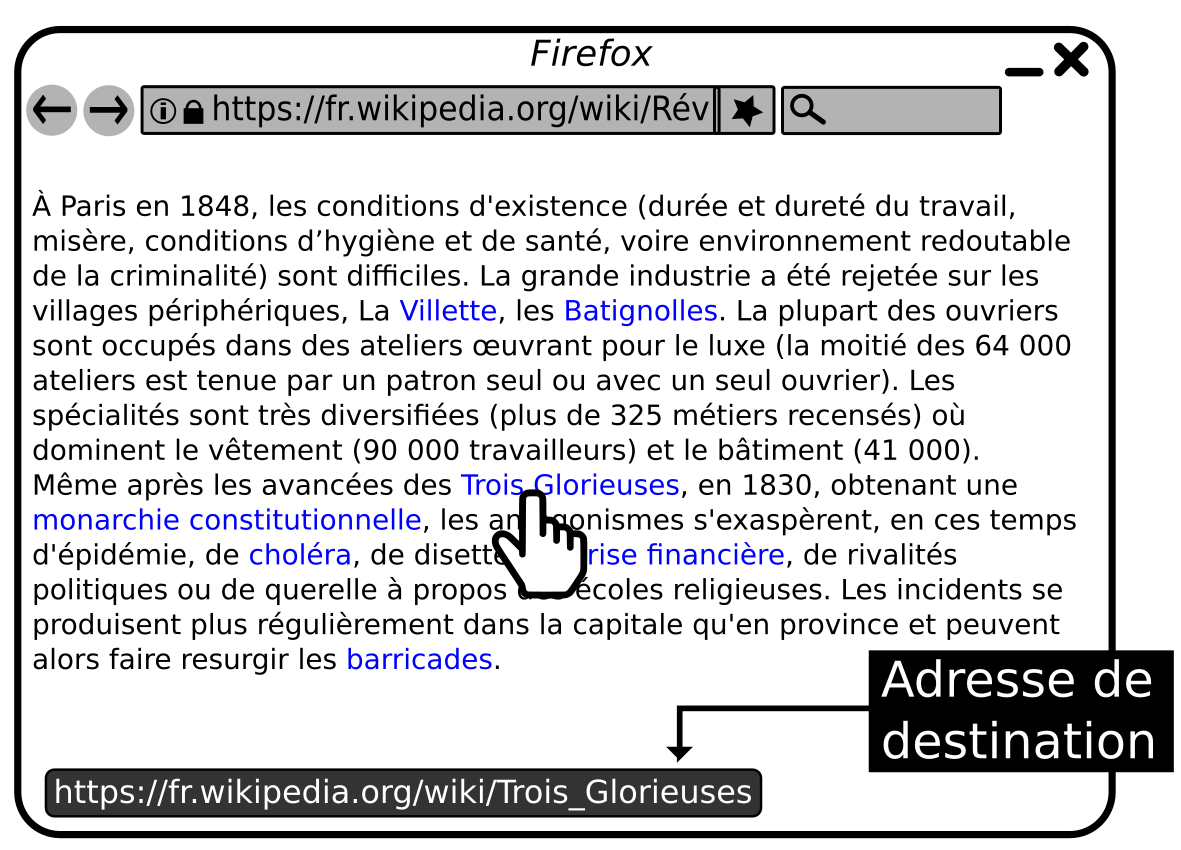
On a tendance à oublier l'affichage de l'URL de destination, car elle se cache souvent derrière le nom littéral des liens des moteurs de recherche et autres sites. Pourtant elle est fondamentale. Lire sa codification n'est pas compliqué et nécessaire pour vérifier la nature de la ressource à laquelle on va accéder en cliquant sur le lien.
Pourquoi les adresses commencent par HTTP ?
HTTP signifie HyperText Transfert Protocol (« protocole de transfert hypertexte »). Comme son nom l'indique, il s'agit d'un protocole technique (des spécifications) qui permet à un programme client (le navigateur, par exemple) et à un serveur (la machine qui héberge le site) de communiquer ensemble. Par ce protocole, lorsque je me rends sur une page de l'encyclopédie Wikipédia, mon navigateur effectue une requête auprès du serveur de Wikipédia, il copie la page que lui renvoie le serveur (contenus textuels, images, etc.), et il affiche la page que je peux lire.
Pour raconter son histoire, le protocole HTTP est la formalisation dans un standard du principe de l'hypertexte, inventé respectivement en 1945 et 1965 par Vannevar Bush et Ted Nelson. On se trouve là aux origines non pas d'Internet mais du système d'échange d'information en réseau. L'internet que nous connaissons aujourd'hui a du transposer techniquement le concept de l'hypertexte pour l'automatiser à travers le protocole HTTP. Et, bien entendu, il existe plusieurs protocoles d'échange sur Internet. Une variante de HTTP est HTTPS, nous en parlerons plus bas et dans le chapitre 5.
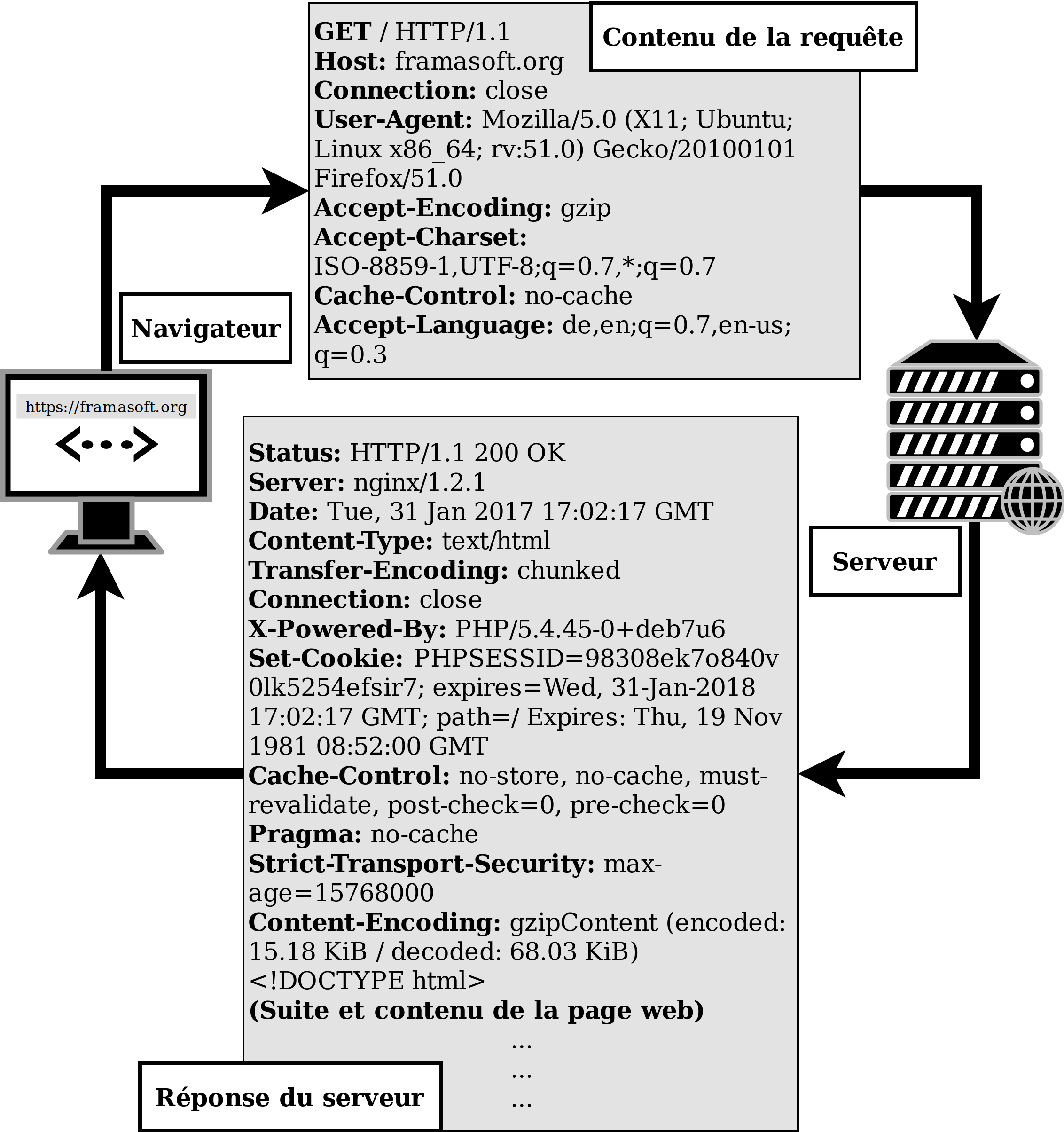
Si on fait le détail, une requête HTTP envoyée par le client consiste à donner au serveur un ensemble d'éléments : la page demandée, les formats d'image acceptés, la langue acceptée, l'identification du navigateur et de sa version, etc. Le serveur, quant à lui (et s'il est bien configuré) renvoie alors des informations qui le concernent, puis ajoute le contenu demandé et si possible de manière à ce que le client puisse le lire correctement en fonction des spécifications qu'il lui a adressé précédemment.
Bref, le serveur vous apporte votre milkshake selon que vous l'avez commandé conformément à la carte des saveurs disponibles et de vos propres goûts. Dans l'illustration ci-dessous, on voit ce que le navigateur envoie au serveur et ce que ce dernier lui répond avant de donner la page à afficher. Ce dialogue est invisible aux yeux de l'utilisateur, mais il donnerait quelque chose comme cela :
Navigateur : — Bonjour, je voudrais recevoir la page Framasoft.org, je suis le navigateur Mozilla Firefox, je tourne sous Linux, je comprends les encodages et les langages que voici.
Serveur : — Enchanté, je peux vous servir. Voici quelques informations sur la manière dont nous préparons votre commande et le fonctionnement de nos cuisines. Ici on fonctionne de manière sécurisée, et d'ailleurs voici un cookie pour accompagner votre commande. Vous trouverez ci-dessous le contenu de la page demandée.
Déchiffrons une URL
Prenons une URL type :
https://fr.wikipedia.org/wiki/Framasoft
Que nous apprend cette URL ? Plein de choses…7
Le plus important : le nom de domaine
https://fr. wikipedia.org /wiki/Framasoft
Il s'agit de l'extension (.org, .net, .com, .fr…) précédée d'un identifiant.
L'extension (aussi parfois appelée domaine de premier niveau) est l'équivalent du code postal qui localise le quartier où se trouve le site. Le nom de domaine correspond alors à la rue.
Il est bon de savoir que les domaines (et sous-domaines que nous allons aborder ensuite), sont toujours écrits du plus précis au moins précis : ainsi, fr.wikipedia.org nous dit que vous visitez le domaine fr qui fait partie de wikipedia, lui-même étant affilié à l'extension org.
 Bon à savoir
Bon à savoir
wikipedia.bill.com, vous n'êtes pas sur Wikipedia. Vous êtes sur une page appartenant à bill.com qui n'a a priori rien de commun avec le réseau Wikipedia et qui peut contenir n'importe quoi. Donc vérifiez toujours que le nom de domaine correspond bien au site que vous souhaitez visiter.
Les hameçonnages en ligne (phishing) fonctionnent souvent de cette manière : vous recevez un courriel avec un intitulé de banque vous demandant d'aller dans votre espace en ligne, avec un lien. Vous cliquez sur le lien et vous arrivez sur un site qui ressemble à s'y méprendre au site de votre banque. Une simple vérification de l'URL permet de déjouer le piège : votre banque devrait avoir un nom de domaine de type nom-de-la-banque.com. Si vous voyez quelque chose comme nom-de-la-banque.quelquechose.com, abstenez-vous de cliquer !
Les URL peuvent être longues et incompréhensibles. Heureusement, de nombreux navigateurs comme Firefox mettent le nom de domaine en évidence. Ainsi, la lecture est facilitée et vous pouvez en un coup d'œil savoir où vous êtes.
Concernant l'extension (.org), elle peut renseigner sur la nature du site. Voici les plus courantes et leurs usages recommandés :
.com: la plus connue, maladroitement considérée comme celle par défaut. Elle signifie pourtant « commercial » et ne devrait être utilisée que par les sites d'entreprises à but lucratif..org: utilisée par les organisations non lucratives (associations, sites communautaires, etc.)..net: sans signification particulière autre que « site web ». Devrait être utilisée par défaut (page perso, etc.)..fr,.de,.co.uk, etc. : extensions spécifiques aux pays. Elles sont gérées par les pays directement et dépendent donc de leurs législations (contrairement aux autres qui sont exclusivement américaines).
Notez qu'il ne s'agit que d'usages recommandés. Ainsi, chacun peut acheter un domaine en .com même s'il n'est pas une entreprise et n'a pas de but lucratif. L'extension peut donc vous informer, mais elle n'a aucune valeur dans l'absolu. Le site http://identi.ca/ n'a par exemple aucun rapport avec le Canada (dont le .ca est pourtant l'extension) : l'extension a simplement été choisie pour permettre la composition du mot Identica.
Le sous-domaine
https:// fr. wikipedia.org/wiki/Framasoft
Il s'agit du mot juste avant le nom de domaine.
Si vous savez déjà où vous êtes par le nom de domaine, cette information est moins importante. Néanmoins, elle est aussi une bonne source de renseignements. Ici, vous savez que vous êtes sur la partie francophone de Wikipédia (la partie anglophone serait en.wikipedia.org).
Si l'on reprend l'exemple de l'adresse postale : vous avez trouvé la rue Wikipedia, le numéro de la maison dans la rue est fr.
De nombreux sites permettent une bonne lisibilité grâce à cela. Les services de Google (même si nous ne les recommandons pas) suivent cette logique :
- Google :
https://google.com/, - Google Maps :
https://maps.google.com/, - Gmail :
https://mail.google.com/, - etc.
La communication est-elle sécurisée ?
https ://fr.wikipedia.org/wiki/Framasoft
Le fameux HTTP (cf. ci-dessus) que l'on retrouve en début de chaque adresse désigne les règles utilisées par les ordinateurs pour s'échanger des données sur la toile (pages web, images, vidéos…).
Mais de plus en plus de sites utilisent désormais HTTPS, le S signifiant « sécurisé ». En effet, les pages en HTTPS sont chiffrées avant d'être transmises : votre navigateur et le site se sont mis d'accord sur une manière de chiffrer leurs communications qu'ils sont seuls à connaître. Une personne qui voudrait espionner la conversation n'y comprendrait rien sans la règle de cryptage.
Grâce à ce sigle, vous pouvez donc savoir très rapidement si les données transitent en clair sur le réseau (HTTP) ou non (HTTPS).
Attention : si cela est effectivement un gage de sécurité pour vos communications, cela ne prouve pas pour autant que le site est sûr en tous points. Par exemple, vous ne pouvez pas savoir ce que le site va faire de vos données personnelles : Facebook est accessible en HTTPS mais n'est pas pour autant respectueux de votre vie privée.
Enfin, il pourra vous arriver d'avoir un message d'avertissement lorsque vous vous connectez à une adresse en HTTPS. Nous vous entendons déjà :
Pourquoi ? si les communications sont sécurisées, n'est-ce pas mieux ?
Oui bien sûr! Mais HTTPS permet deux choses : tout d'abord de sécuriser ce qui transite dans les tuyaux d'internet, mais aussi garantir que le site que vous visitez est bien authentique. Pour cela, chaque site a enregistré un certificat auprès d'un organisme vérifiant son identité.
Par exemple, lorsque votre navigateur se connecte à Wikipédia en HTTPS, il récupère le certificat du site et demande à l'organisme associé au certificat si celui-ci est authentique. Si ce n'est pas le cas, une page d'avertissement est affichée : les données seront bien chiffrées, mais il est possible que quelqu'un vous fasse croire qu'il est Wikipédia.
Par conséquent, il se peut que vous arriviez sur un site en HTTPS avec un avertissement sur le certificat : si vous n'êtes pas sûr, n'y allez pas !
Nous reprenons ces éléments de sécurité dans le chapitre 5. Reportez-vous y pour plus de détails. En attendant, nous poursuivons notre analyse d'URL.
Où suis-je dans le site ?
fr.wikipedia.org /wiki/Framasoft
Il s'agit du chemin d'accès. Il correspondrait aux indications que vous donneriez au livreur : « Première porte à droite, après l'escalier… ».
Cette dernière information peut également vous servir si le site a une architecture visible. Ici, nous savons que nous parcourons le wiki (un gestionnaire de contenus) et que nous sommes sur l'article Framasoft.
Cette partie de l'URL est la dernière et n'est pas vraiment normée : certains sites affichent des choses claires comme ici (le nom de l'article est inscrit littéralement dans l'URL), d'autres afficheront des identifiants abscons pour chaque page.
Un petit détail qui peut néanmoins vous sortir de problèmes idiots : si vous avez cliqué sur un lien (dans un forum par exemple) et que la page est inaccessible (erreur 404), vérifiez la fin de l'URL. Il n'est pas rare qu'un lien soit erroné parce qu'il contient un caractère de trop : l'auteur peut avoir malencontreusement inclus la virgule de sa phrase dans l'adresse, provoquant une erreur. Ainsi, si l'adresse finit par index.html), vous pouvez vous attendre à avoir une erreur : retirez simplement la parenthèse à la main et rechargez la page.
Notions de HTML ou pourquoi le surf n'est pas si simple
Si vous vous souvenez de la question des requêtes HTTP, que nous avons vue ci-dessus, vous n'avez pas oublié que le serveur envoie le résultat de la commande au navigateur de manière à ce que celui-ci puisse l'afficher. Il peut aussi, à défaut, proposer à l'utilisateur un autre programme pour traiter le contenu demandé. Ainsi, par exemple si vous cliquez sur le lien vers un document PDF, c'est le lecteur PDF qui sera sollicité par le navigateur ou bien il vous sera proposé de télécharger le fichier ou encore de l'ouvrir avec un programme de votre choix.
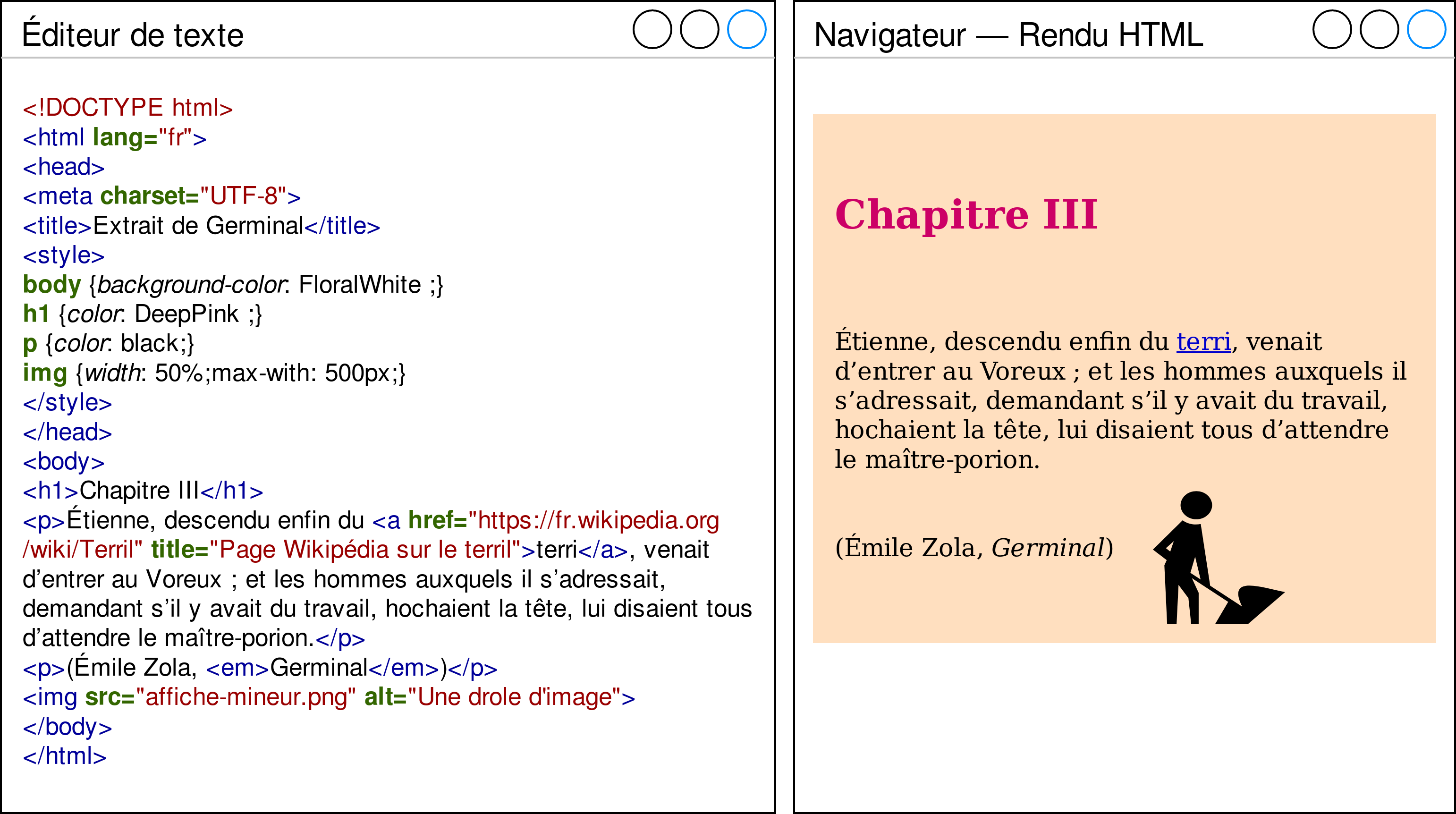
Pour mieux comprendre comment fonctionnent les pages internet sur lesquelles vous surfez, il faut comprendre comment l'hypertexte est utilisé. Fondamentalement, c'est très simple. L'illustration ci-dessous montre à gauche la rédaction HTML d'une page et à droite le résultat affiché sur un navigateur.
Sans entrer dans le détail, nous allons commenter les différents blocs.
<!DOCTYPE html>: c'est la ligne qui permet de déclarer la grammaire ou la norme du document. Ici nous traitons d'un document rédigé en HTML, mais il y a d'autres possibilités.<html lang="fr">: nous ouvrons le contenu qui sera encapsulé entre les balises<html>et</html>tout en indiquant que la langue du document est le français.- Entre les balises
<head>et</head>nous trouvons, dans l'ordre d'apparition : la déclaration d'encodage (UTF8), le titre de la page, et, entre les balises<style>et</style>, les styles à appliquer aux différents éléments de mise en page. Par exemple les titresH1seront dans la couleurDeepPink(rose foncé / magenta). Notons que les styles à appliquer peuvent être tous regroupés dans un fichier de style à part (il s'agit alors d'un fichier portant l'extension.css, pour Cascading Style Sheet). - Entre les balises
<body>et</body>, nous trouvons le corps du document, c'est-à-dire le contenu informatif qui sera affiché selon les spécifications de mise en page précisées dans les styles. <h1>Chapitre III</h1>: il s'agit d'un niveau de titre.- Les balises
<a>et</a>servent à créer des liens. Ici le lien est le mot « terri » et la cible est une page Wikipédia. - Les balises
<p>,</p>et<em>,</em>sont relatives à la mise en page et la typographie, elles indiquent respectivement le début et la fin d'un paragraphe, et le début et la fin d'une emphase (italique). - Enfin, la balise
<img>sert à traiter des images. Ici nous insérons (avecsrc=) une image en indiquant le nom du fichier.
Bien sûr, cet exemple de page web est simplissime. Mais nous voyons déjà que pour lire une telle page dans votre navigateur, il faut :
- que le navigateur et le serveur soient entrés en communication selon un protocole d'accord qui permet au navigateur de récupérer une page du serveur et l'afficher de manière à ce que vous puissiez la lire ;
- que la page soit correctement écrite en HTML (c'est-à-dire que son créateur n'ai pas fait d'erreur en la composant) ;
- que les fichiers auxquels la page fait appel (ici un fichier image et éventuellement un fichier de styles) soient disponibles.
Dans des cas plus complexes, sur la majorité des sites web que vous fréquentez :
- les pages font souvent appel à des bases de données (ne serait-ce que pour entrer un identifiant et un mot de passe pour accéder à des contenus spécifiques) ;
- des technologies autres que le langage HTML sont souvent sollicitées (Javascript, Ajax, PHP… autant de noms barbares qui ne font que traiter des contenus et des données échangées).
Pour résumer, surfer sur Internet, c'est faire appel à toutes ces techniques, langages, contenus et données, souvent à vitesse grand V, pour lire, écouter, visualiser des contenus gentiment fournis par les serveurs et copiés sur votre machine (dans les dossiers de cache de votre navigateur). Si vous avez des difficultés à lire un site web et que vous êtes sûr-e de la bonne configuration de votre machine et de votre connexion, c'est parce que ces éléments ne fonctionnent pas toujours en même temps de la meilleure manière, en particulier si le serveur de la base de données tombe en panne ou se trouve ralenti.
Je dois accepter des conditions d'utilisation
Les conditions d'utilisation des contenus sur Internet concernent à la fois la manière dont les contenus sont accessibles et les conditions d'usage des services qui distribuent ces contenus. Selon quels critères les contenus web sont-ils compatibles avec les technologies que vous utilisez et pourquoi certains sites et services imposent-ils des conditions d'utilisation ? Certains droits d'usage sont cependant beaucoup plus attentifs aux libertés des utilisateurs.
Accès égalitaire : le rôle du W3C
L'un des facteurs qui a contribué à la fois à la croissance de l'économie d'Internet et à l'extension de ses valeurs sociales de partage, c'est la possibilité d'utiliser des protocoles ouverts pour pouvoir communiquer sur le réseau. Sans l'ouverture de ces protocoles, les navigateurs ne pourraient pas tous communiquer de la même manière avec les serveurs, nous ne pourrions pas envoyer de courriels entre abonnés de différents services, il y aurait même peut-être plusieurs réseaux Internet différents sans correspondance entre eux…
Pourtant, utiliser de manière égalitaire des spécifications techniques n'est pas suffisant. Il faut encore que les éditeurs de contenus puissent présenter ceux-ci de façon cohérente, de manière à ce qu'un article mis en ligne en France, soit lisible de la même manière partout dans le monde quelle que soit l'origine de la connexion ou le navigateur employé.
C'est à cela que s'emploie le World Wide Web Consortium (W3C) depuis 1994. Le W3C est un organisme à but non lucratif, possédant des antennes un peu partout dans le monde. Il s'emploie à émettre des recommandations visant à garantir la compatibilité des technologies web, comme le HTML que nous venons de voir dans la section précédente. Il peut s'agir de langages web, de format d'images, de méthodes d'exploitation de bases de données, d'accessibilité, etc. Notez qu'il ne s'agit pas de certification, comme le ferait une instance de normalisation. Le W3C émet des recommandations suivant une méthodologie précise et exigeante : si les éditeurs, fabricants ou développeurs choisissent de ne pas respecter ces recommandations, c'est alors à eux de s'en expliquer, avec tous les risques de rejet que cela comporte.
En la matière, le monde des développeurs web se souvient des frasques de Microsoft Internet Explorer 6, qui avait beaucoup de mal à assurer une compatibilité acceptable avec les contenus. Les développeurs ont même dû créer des solutions complexes de paramétrage pour ne pas pénaliser les utilisateurs d'IE6 qui, autrement, auraient eu de grandes difficultés pour accéder aux contenus.
Aujourd'hui, la mention « ce site est optimisé pour la version Y du navigateur X » a pratiquement disparu, justement grâce aux travaux du W3C. Dès lors, si vous avez des difficultés avec un navigateur récent et dont vous avez assuré la mise à jour, il y a fort à parier que les problèmes d'affichage proviennent des développeurs et non de votre fait.
Néanmoins, des technologies sont souvent utilisées bien qu'elles ne fassent pas partie des recommandations du W3C. C'est le cas de Adobe Flash, un logiciel tout droit issu des années 1990, qui permet de créer et afficher des applications fonctionnant sur le navigateur disposant d'une extension Flash. Certains sites proposent ainsi des animations, souvent lourdes à charger et dont la fiabilité en termes de sécurité peut laisser à désirer. Il s'agit par exemple de petits jeux en Flash, ou encore d'une animation sur la page d'accueil d'un site (souvent bien inutile). Certains grands éditeurs comme Apple, Google et Microsoft prennent de plus en plus leurs distances vis-à-vis de cette technologie, qui est désormais supplantée par le HTML5 (c'est-à-dire la nouvelle version de HTML qui intègre déjà des couches permettant de développer des applications et afficher, par exemple, des contenus multimédia cohérents et répondant aux spécifications du W3C).
Gérer ses plugins pour choisir ses contenus
Heureusement, les navigateurs disposent de moyens pour décider si l'on veut ou non utiliser de telles technologies. La plupart du temps, les commandes sont directement accessibles dans la fenêtre dès lors que la navigateur fait appel à une extension pour afficher des contenus. Dans le cas de Flash, il faut une extension Flash-Player que l'on peut activer ou désactiver au besoin.
Dans l'illustration suivante, on apprend que les plugins (extensions) en cours d'utilisation sont symbolisés par un petit bloc de Lego dans la barre d'adresse. On peut alors désactiver l'extension si elle est active ou choisir de l'activer si elle ne l'est pas par défaut.
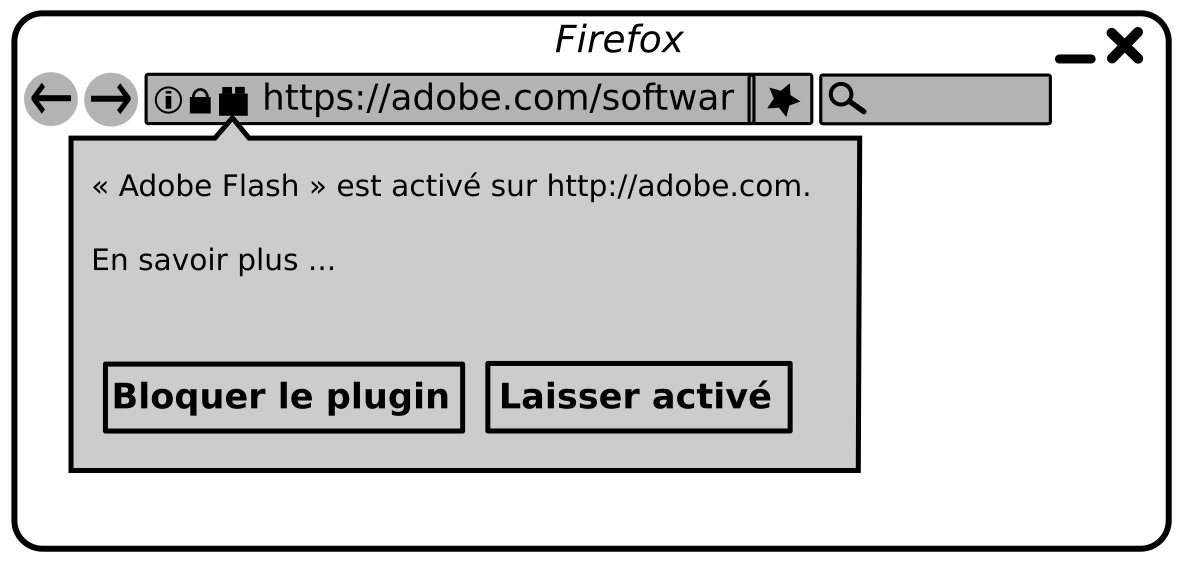
De manière générale, un bon navigateur est un navigateur qui vous permet de choisir les contenus, en particulier lorsque certains vous sont imposés et ne sont pas forcément pertinents pour votre navigation. De bons outils pour cela se nomment plugins ou extensions ou encore modules complémentaires et vous permettent d'étendre les fonctionnalités de votre navigateur.
La fondation Mozilla propose ainsi pour Firefox une pléthore de modules développés par la communauté, et que l'on peut installer facilement. Dans le chapitre 5, par exemple, le module Privacy Badger vous est présenté pour éviter le traçage des sites web et protéger votre confidentialité.
Voici quelques exemples de modules sympathiques :
- pour éviter les publicités intempestives, vous pouvez installer uBlock Origin ;
- pour corriger ce que vous écrivez dans le navigateur (par exemple lorsque vous écrivez un courriel depuis un webmail), vous pouvez utiliser Grammalecte ;
- vous pouvez aussi utiliser un service en ligne et établir un pont avec le contenu apparaissant dans le navigateur ; c'est l'exemple de Framabag, un service basé sur Wallabag et qui vous permet de stocker en ligne des pages web (comme un article) puis de les consulter plus tard à tête reposée, sur votre mobile, par exemple.
Pour installer un module pour Firefox, il suffit de vous rendre sur le site-dépôt des modules, choisir un module et cliquer sur « Ajouter à Firefox ». Un script (petit programme) permettra alors à Firefox de télécharger et installer le module.
Un autre moyen consiste à se rendre dans le gestionnaire de modules de Firefox et choisir dans le « catalogue ». Pour gérer les modules, les activer, les désactiver, les supprimer, allez dans le gestionnaire de modules puis dans « Extensions ».

En somme, vous avez compris que les bons usages des technologies web et des navigateurs sont ceux qui vous laissent la liberté de lire des contenus comme vous le voulez. L'ajout de contenus non pertinents, comme des publicités intrusives, peut gâcher votre lecture et vous amène à équiper votre navigateur avec des modules adaptés. Cependant, certains modules, parce que leur fonctionnement implique un traitement des informations, peuvent dégrader la rapidité de votre navigateur. D'autres modules sont en revanche très utiles, permettent davantage de confort et sont même parfois addictifs.
Les Conditions Générales d'Utilisation (CGU)
Les CGU se trouvent généralement par un lien en bas de page du site que vous consultez ou du service que vous utilisez. Pourquoi existe-t-il des CGU ?
Il s'agit d'abord d'un contrat entre l'éditeur et l'utilisateur qui vise à mettre au clair les conditions dans lesquelles l'éditeur met un contenu ou un service à disposition et celles dans lesquelles un utilisateur est en mesure d'en user. Les CGU déterminent alors les responsabilités de l'un et de l'autre et peuvent aussi mentionner des sanctions éventuelles.
Par exemple, un forum peut rappeler dans ses CGU que les propos racistes et injurieux sont punis par la loi, il peut stipuler que l'éditeur ne saurait être tenu responsable des propos écrits par les membres mais que ces derniers peuvent se trouver bannis du forum au cas où ils écriraient de tels propos.
Le fait d'utiliser un site ou un service équivaut à accepter les CGU, mais bien peu d'internautes prennent le temps ne serait-ce que survoler ces textes.
Prenons l'exemple des CGU de Google. On ne peut pas reprocher à cette firme d'être opaque sur ses CGU puisqu'elle les rappelle régulièrement via un message d'alerte lorsque vous effectuez une recherche sur son site le plus utilisé, son moteur de recherche. Dans les CGU de Google, on trouve8 :
Certains de nos Services vous permettent d'importer, de soumettre, de stocker, d'envoyer ou de recevoir des contenus. Vous conservez tous vos droits de propriété intellectuelle sur ces contenus. En somme, ce qui est à vous reste à vous.
Lorsque vous importez, soumettez, stockez, envoyez ou recevez des contenus à ou à travers de nos Services, vous accordez à Google (et à toute personne travaillant avec Google) une licence, dans le monde entier, d'utilisation, d'hébergement, de stockage, de reproduction, de modification, de création d'œuvres dérivées (des traductions, des adaptations ou d'autres modifications destinées à améliorer le fonctionnement de vos contenus par le biais de nos Services), de communication, de publication, de représentation publique, d'affichage public ou de distribution publique desdits contenus. Les droits que vous accordez dans le cadre de cette licence sont limités à l'exploitation, la promotion ou à l'amélioration de nos Services, ou au développement de nouveaux Services. Cette autorisation demeure pour toute la durée légale de protection de votre contenu, même si vous cessez d'utiliser nos Services […].
Il est vrai que la tournure est parfois alambiquée. Ici, on peut imaginer une certaine contradiction entre les deux paragraphes, l'un stipulant que nous conservons tous nos droits sur nos données, et l'autre impliquant que Google peut en faire à peu près ce qu'il veut. En réalité, vous conservez effectivement tous vos droits sur les données, mais le fait d'utiliser les services de Google implique que vous donnez une licence d'usage à Google et que cette licence n'est pas censée prendre fin, même si vous n'utilisez plus les services en question.
Notez aussi que, selon le pays du site ou du service que vous utilisez, les CGU peuvent non seulement être rédigées dans une langue que vous ne comprenez pas, mais aussi emporter des conditions parfaitement légales dans le pays en question et non dans le vôtre. Dans ce cas, tout contentieux risque d'être bien difficile à résoudre (ceci sans compter le lieu où vos données sont stockées, en particulier si les serveurs ne sont pas sur le sol français).
Les clauses des CGU de Google constituent un cas d'école. Heureusement, tous les sites et services sur Internet n'usent pas de telles libertés qui, si elles sont relativement légales, impliquent cependant des pratiques qui ne sont pas vraiment loyales. En contraste, une association comme Framasoft, qui propose elle aussi des services en ligne et des contenus, affiche des CGU claires et pédagogiques qui stipulent notamment qu'aucune exploitation ne sera faite des données. Les CGU de Framasoft visent essentiellement à rassurer les utilisateurs, agir en transparence et prévenir des risques d'abus.
Cadre légal
Sur Internet, les cas d'abus ne manquent pas. Lors de l'ouverture du service Framasphère, un nœud du réseau social Diaspora*, l'association Framasoft a du faire face à plusieurs cas de manquement au règlement et à la loi, comme par exemple l'usage non autorisé de photographie d'un tiers, des usurpations d'identité, etc. Heureusement, les coordonnées des responsables du site et leur réactivité ont permis à chaque fois une résolution adéquate des situations. Ce n'est malheureusement pas le cas partout, en particulier s'il s'agit de services aux conditions d'utilisation douteuses.
Tous les sites et services qui enregistrent des données personnelles, ne serait-ce que vos noms et prénoms, doivent faire l'objet d'une déclaration à une autorité qui va étudier à la fois ce que les services font avec ces données, comment ils le font, s'ils les transfèrent ou non dans un autre pays, et les informations qu'ils en infèrent. Pour la France, c'est la CNIL (Commission nationale de l'informatique et des libertés) qui est en charge de traiter et surveiller les déclarations de ce type. Pour les autres pays, vous pouvez vous reporter à la carte éditée par la CNIL sur son site : en cliquant sur un pays vous pourrez savoir s'il existe une autorité équivalente, quelles sont les dispositions législatives concernées, et les coordonnées des points de contacts officiels.
Pour la CNIL, ce qu'on appelle « données personnelles » est défini relativement à l'article 2 de la Loi Informatique et Libertés :
Constitue une donnée à caractère personnel toute information relative à une personne physique identifiée ou qui peut être identifiée, directement ou indirectement.
L'éditeur d'un site ou d'un service, dans la mesure où il utilise des données personnelles de ses utilisateurs, en constitue donc un fichier destiné à être exploité. C'est ce fichier et ses spécifications qui doivent être déclarés. En France, les manquements en termes de conformité CNIL de ces fichiers est punissable de 300 000 euros et de 5 ans d'emprisonnement.
Vous aurez compris qu'avant d'entrer vos données d'identité, votre adresse ou tout autre information personnelle sur un site ou un service, il est de votre intérêt de vérifier auparavant quelques éléments :
- si l'éditeur a enregistré son site ou son service auprès de la CNIL ou un équivalent dans le pays concerné. Généralement, la mention de l'enregistrement et même le numéro sont accessibles dans la partie « À propos » ou « Mentions légales », souvent un lien en pied de page ;
- en cas de doute, vérifiez auprès d'un annuaire pour retrouver l'identité de l'éditeur : une recherche WHOIS (qui est…?) auprès de l'AFNIC9, par exemple, vous permet, à partir d'un nom de domaine, de trouver l'identité de celui qui a déclaré ce domaine. Cela ne signifie pas pour autant que c'est cette personne qui édite effectivement le site, mais c'est une indication pertinente ;
- renseignez-vous sur les moyens à votre disposition pour effectuer des démarches afin de récupérer vos droits (droit à l'image, droit d'auteur, autres informations personnelles, etc.) : le site de l'éditeur doit mentionner une adresse à laquelle vous pouvez écrire (en conservant une copie de votre message) et sur son site, la CNIL vous donne quelques astuces pour mener à bien ce type de démarche.
Les droits d'usage
Toute l'histoire d'Internet repose sur les notions de partage : partage du code, partage des connaissances, partage des techniques, et toutes ces conditions qui firent qu'Internet a été construit comme un réseau libre et ouvert. Dès lors, que pouvez-vous faire avec les contenus que vous lisez, copiez ou téléchargez sur Internet ? Cette question est vaste et appellerait un développement bien trop long pour cet ouvrage, surtout parce qu'elle traite du droit d'auteur. Nous allons donc devoir prendre quelques raccourcis : reportez-vous aux références citées si vous désirez en savoir davantage.
Partager ?
Lorsque nous disons qu'Internet a été construit sur des valeurs de partage, que voulons-nous dire exactement ? Non pas que la structure technologique des premiers ordinateurs en réseau ait été développée de manière anarchique, d'autant plus que les premiers projets de développement aux États-Unis ont été en partie portés par des fonds militaires à la fin des années 1960. Ce que cela signifie, c'est que la communauté des développeurs des protocoles et des programmes qui ont permi de faire fonctionner un réseau et des serveurs, l'a fait dans un esprit d'ouverture.
L'exemple typique est les RFC (Requests For Comments), littéralement, les « demandes de commentaires ». Elles concernent différents aspects techniques d'Internet ou matériels. Ces RFC sont regroupées en une série qui démarre en 1969. Le principe : à l'initiative d'un volontaire (tout le monde peut proposer une RFC), un brouillon est proposé à toute la communauté puis, si ce brouillon retient l'attention et après discussion générale et publique, une rédaction finale est tenue à disposition de tous. Les RFC sont toutes rédigées de la même manière et expriment des exigences (obligations, restrictions, recommandations…). C'est notamment grâce à ce partage des connaissances et des techniques qu'Internet a modélisé tous les outils qui permirent aux utilisateurs de collaborer et construire une communauté mondiale, avec une économie, des entreprises, etc.
Pourtant, dans ce monde de partage, comment comprendre cet apparent paradoxe que tous les partages ne sont pas permis et même sanctionnés par différentes lois ? Plus troublant encore, si l'on considère ce vaste projet de partage qu'est Wikipédia, on apprend assez vite que l'utilisation des contenus de Wikipédia est soumise à certaines contraintes.
Droit d'auteur
Le droit d'auteur est un droit qui s'applique aussi bien sur Internet qu'ailleurs. Simplement, le développement d'Internet a quelque peu bousculé les pratiques.
Le droit d'auteur est acquis de manière automatique dès lors que vous créez une œuvre. Il y a deux acceptions à ce droit d'auteur :
- un droit moral, qui permet d'attribuer à l'auteur la paternité de son œuvre et protège l'intégrité de cette œuvre,
- un droit patrimonial, par lequel un auteur peut diffuser son œuvre ou céder l'exclusivité de la production et de la distribution à un tiers (un éditeur, par exemple).
La diffusion et la multiplication des contenus sur Internet rend plutôt difficile la régulation du droit d'auteur. Si vous vous souvenez des CGU de Google dont nous avons parlé ci-dessus, la jurisprudence peut prêter à sourire si elle ne reflétait de graves difficultés à faire respecter le droit d'auteur sur Internet. Ainsi, le Tribunal de Grande Instance de Paris a jugé une affaire le 9 octobre 2009. Cette affaire opposait un photographe, une société éditrice de photographie, un site Internet et la société Google Image. Pour résumer : une photographie disponible sur le site a été reprise par Google Image mais le nom de l'auteur n'ayant pas été mentionné, le TGI, sur demande du photographe à déréférencer son œuvre, a condamné Google Image. À travers cette affaire, on voit clairement les difficultés que les auteurs peuvent avoir pour protéger leur droit moral à la paternité (la photographie ayant été retouchée sans mentionner le nom de l'auteur), et même le droit patrimonial (la société éditrice en charge de la distribution de l'œuvre doit elle aussi être de la partie plaignante).
Évidemment on comprend aussi que, étant donné la mondialisation du réseau, les acceptions du droit d'auteur ne sont pas les mêmes dans tous les pays, exception faite des pays signataires de la Convention de Berne qui s'accordent sur une majorité de principes. C'est pourquoi des déséquilibres et des tensions ont cours sur Internet à propos du respect des droits d'auteur, et ne sont pas forcément le fait des piratages et autres pratiques, condamnables, mais dont le caractère illicite est néanmoins très clair… Jusqu'à ce que vous compreniez que dans la mesure où toute consultation de contenu sur Internet est une copie, ce n'est plus seulement l'appropriation illicite d'une œuvre qui est en jeu mais la méthode de sa distribution et les droits de diffusion et reproduction (c'est pourquoi les sites pirates sont généralement condamnés pour contrefaçon et non pour distribution illégale de copies).
Concrètement, face à cette complexité, l'utilisateur doit respecter certains principes relativement simples. En voici quelques-uns que vous avez tout intérêt à retenir :
- vous pouvez utiliser une œuvre (un contenu créé par quelqu'un d'autre que vous, qu'il s'agisse de programme, image, texte, etc.), pour la diffuser d'une manière ou d'une autre, uniquement à partir du moment où vous êtes en mesure de savoir que vous avez effectivement le droit d'en disposer, dans quelles conditions et si et seulement si vous en attribuez la paternité à l'auteur (vous citez l'auteur) ;
- vous pouvez citer une partie courte d'un texte (le droit de citation est une exception au droit d'auteur) à la condition d'en attribuer la paternité et d'indiquer la source de l'œuvre,
- vous pouvez indiquer la provenance d'une œuvre sur Internet ou faire un lien vers cette œuvre mais vous n'avez pas la possibilité de vous en autoriser vous-même le droit de diffusion.
Si le respect du droit d'auteur doit s'appliquer sur Internet comme ailleurs, il reste que la concentration des contenus sur Internet par de grands monopoles ont réussi en peu d'années à créer des inégalités et des injustices. On peut se reporter à l'ouvrage de Joost Smiers et Marieke van Schijndel, Un monde sans copyright et sans monopole, qui, après un état des lieux des distorsions du droit d'auteur par les monopoles économiques (pays ou grandes firmes) propose de se passer complètement du copyright (et donc du droit d'auteur) pour créer un nouveau modèle économique. Pour illustrer cela, on peut citer la concentration des publications scientifiques par de grands éditeurs comme Elsevier, des éditeurs « papier » au départ et qui, après avoir racheté de multiples autres éditeurs, ont créé des monopoles sur l'édition et la distribution (numérique et papier) des publications scientifiques. Aujourd'hui des millions d'euros de fonds publics partent entre leurs mains, ce qui crée une grande inégalité à l'échelle mondiale sur l'accès aux connaissances scientifiques10.
De nouveaux équilibres du droit d'auteur
Licences libres
Les licences libres ne concernent pas seulement les logiciels (voir le chapitre 1, où nous définissons une licence libre). Elles dépassent largement le cadre de l'usage des programmes car leur objectif n'est pas seulement de partager un bien mais aussi de partager ce qu'on peut faire de ce bien. Ainsi un morceau musical sous licence libre peut être remixé et re-partagé, un texte peut être traduit (c'est-à-dire modifié) et cette traduction peut être diffusée, etc.
En fait, les licences libres ne s'opposent pas au droit d'auteur — elles tendraient même à le renforcer — mais s'opposent à la notion d'exclusivité et de concentration des droits, pour donner à l'auteur la possibilité de déterminer a priori les conditions d'usage de son œuvre. Ainsi, il est non seulement possible de placer une œuvre non-logicielle sous licence libre, mais cela équivaut à une démarche spécifique de l'auteur qui souhaite verser sa production dans les biens communs. Ce faisant, il ne renie pas le droit moral d'auteur car ce dernier est inaliénable : quoi qu'il arrive, l'auteur est toujours reconnu comme auteur, même lui ne peut pas dénier cette qualité (dans l'état actuel du droit).
L'encyclopédie Wikipédia est une illustration convaincante de ce que les licences libres permettent non seulement de partager des contenus mais aussi de participer à leur création, qu'il s'agisse de connaissances, d'illustrations, de photographies ou de vidéos. Les contenus de Wikipédia sont placés sous licence Creative Commons attribution, partage dans les mêmes conditions : cela signifie que vous pouvez utiliser et partager ces contenus dans la mesure où vous en citez la source et que la licence de ce que vous partagez en provenance de Wikipédia soit cette même licence. En d'autres termes, conformément au droit d'auteur, vous ne pouvez pas vous attribuer la paternité de ce contenu, vous devez citer Wikipédia au titre de cette paternité. Par contre, en plus, vous pouvez modifier ce contenu à condition de renseigner ce que vous avez modifié, et vous pouvez diffuser comme vous l'entendez à condition d'utiliser la même licence.
Désormais, vous savez quoi répondre à votre enfant qui prétend qu'il peut utiliser des contenus Wikipédia pour son devoir d'Histoire : il peut citer, mentionner la source, mais en aucun cas prétendre en être l'auteur. Quant au professeur qui ne supporte pas Wikipédia, vous lui pouvez rappeler que le problème n'est pas dans le fait d'utiliser ou non des contenus de Wikipédia, mais dans le fait de s'attribuer ces contenus sans en citer la source. Vous pouvez aussi ajouter que si les contenus de Wikipédia ne le satisfont pas, il peut lui aussi y contribuer en corrigeant ou créant des notices…
Pour utiliser des contenus sous licence libre, vous devez distinguer les licences entre elles. Pour débuter, il est inutile d'entrer dans le détail, mais sachez simplement que toutes les licences libres imposent des conditions qui ne sont pas tout à fait les mêmes. En général on distingue :
- les licences libres : vous pouvez utiliser, partager, modifier et diffuser la modification, exactement comme s'il s'agissait d'un logiciel libre (cf. les 4 libertés dans le chapitre 1) ;
- les licences libres copyleft : copyleft est un jeu de mot signifiant gauche d'auteur par opposition au copyright ; cela signifie que l'œuvre, modifiée ou non, doit être redistribuée exclusivement sous la même licence que celle de départ ;
- les licences de libre diffusion : certaines clauses ne sont pas compatibles avec les 4 libertés, mais l'usage de l'œuvre est tout de même facilité.
Voici quelques exemples de licences pouvant s'appliquer à des contenus culturels, scientifiques ou artistiques :
| Nom de la licence | Abréviation | Caractéristique |
|---|---|---|
| Licence Art Libre | LAL | Licence libre copyleft |
| Licence de documentation libre | GNU FDL | Licence libre copyleft |
| Creative Commons - Attribution | CC-BY | Licence libre non copyleft |
| Creative Commons - Attribution - Partage des conditions initiales à l'identique | CC-BY-SA | Licence libre copyleft |
| Creative Commons - Attribution - Pas de modification | CC-BY-ND | Licence de libre diffusion |
| Creative Commons - Attribution - Pas d'utilisation commerciale | CC-BY-NC | Licence de libre diffusion |
| Creative Commons - Attribution - Pas d'utilisation commerciale - Partage des conditions initiales à l'identique | CC-BY-NC-SA | Licence de libre diffusion |
Creative Commons - Attribution - Pas d'utilisation commerciale - Pas de modification | CC-BY-NC-ND | Licence de libre diffusion |
En guise d'application, voici une bande dessinée sous licence libre CC-By-SA, que nous avons modifié (nous avons traduit les dialogues). Il est important de bien référencer, ce que nous faisons ci-dessous.

- Œuvre originale : Mimi and Eunice, par Nina Paley, sur mimiandeunice.com.
- Source : publication en 2011, à l'adresse : http://mimiandeunice.com/2011/08/30/permission-2/.
- Traduction et modification par Framatophe.
- Licence : CC-BY-SA.
7. Merci en particulier à Gee et Pyves pour la contribution à cette section. ↩
8. CGU consultées le 01/02/2017. ↩
9. L'AFNIC est l'Association Française pour le Nommage Internet en Coopération. Elle se définit ainsi sur son site afnic.fr : « L'Afnic est le centre de gestion (registre) et de ressources des noms de domaine Internet géographiques pour la France (le.fr), l'Ile de la Réunion (le.re), Saint-Pierre et Miquelon (le.pm), Mayotte (le.yt), Wallis et Futuna (le.wf) et les Terres australes et antarctiques Françaises (le.tf). » ↩
10. C'est ce qui a poussé des étudiants et des chercheurs à créer Sci-Hub, un portail qui permet d'accéder aux articles scientifiques gratuitement à la manière des sites de piratage de films. ↩